Venture funding reached a record-shattering $300 billion in Q1 2026 as investors pivot toward agentic AI and energy infrastructure, marking a new industrial era.


Microsoft is betting that two AI models working together are better than one, and it just shipped the proof.
As of this morning, Microsoft’s approach to enterprise AI took a notable turn. The company announced a batch of updates to Microsoft 365 Copilot that include a feature called Critique, the broader availability of Copilot Cowork, and a new Model Council capability. All of them point toward a future where multiple AI models collaborate within a single workflow rather than competing for dominance. These aren’t incremental polish. They represent a real philosophical shift in how Microsoft thinks about AI reliability, and they arrive at a moment when the company badly needs to accelerate Copilot adoption across its massive customer base.
So let’s break down what’s new, why it matters, and what it signals about where enterprise AI is heading.
Critique is a new feature inside Copilot’s Researcher agent, and its premise is elegantly simple. Instead of having one AI model do all the work, you split the job between two. OpenAI’s GPT handles the initial drafting: planning a research task, synthesizing sources, and generating a comprehensive response. Then, before that response ever reaches the user, Anthropic’s Claude steps in as a reviewer, evaluating the draft for accuracy, completeness, and citation quality.
Think of it as a built-in editorial layer. One model writes. Another model fact-checks. The division of labor mirrors how human research teams actually operate. The person who drafts a report is rarely the same person who reviews it. By separating generation from evaluation, Microsoft is tackling one of the most persistent pain points in AI-assisted work: that nagging question of whether you can actually trust what the model just told you.
The results, at least by Microsoft’s own metrics, are significant. The company reports that the multi-model Critique workflow improved Researcher’s score on the DRACO benchmark (an industry measure of deep research accuracy, completeness, and objectivity) by 13.8%. According to Microsoft, that puts Copilot Researcher ahead of standalone deep-research tools from OpenAI, Google, Perplexity, and Anthropic individually.
Microsoft has also indicated that the workflow will eventually become bidirectional, meaning Claude could draft while GPT critiques. The flexibility to swap roles depending on the task suggests this isn’t just a one-off integration. It looks like the beginning of a broader multi-model architecture.
Alongside Critique, Microsoft introduced Model Council, a feature that lets users compare responses from different AI models side by side within the Researcher experience. Rather than receiving a single blended answer, users can see where models agree, where they diverge, and what unique perspectives each one brings to the table.
This is a subtle but important move. One of the biggest barriers to AI trust in enterprise settings is the black-box problem. Users get an answer, but they have no way to gauge its reliability beyond their own expertise. Model Council doesn’t eliminate that problem, but it gives users a much richer signal. If two independent models arrive at the same conclusion through different reasoning paths, your confidence goes up. If they disagree sharply, that disagreement itself is valuable. It tells you to dig deeper before acting.
For research-heavy roles like analysts, consultants, legal professionals, and strategists, this kind of comparative visibility could be genuinely transformative. It moves AI from “here’s an answer, take it or leave it” to “here are multiple informed perspectives, now you decide.”
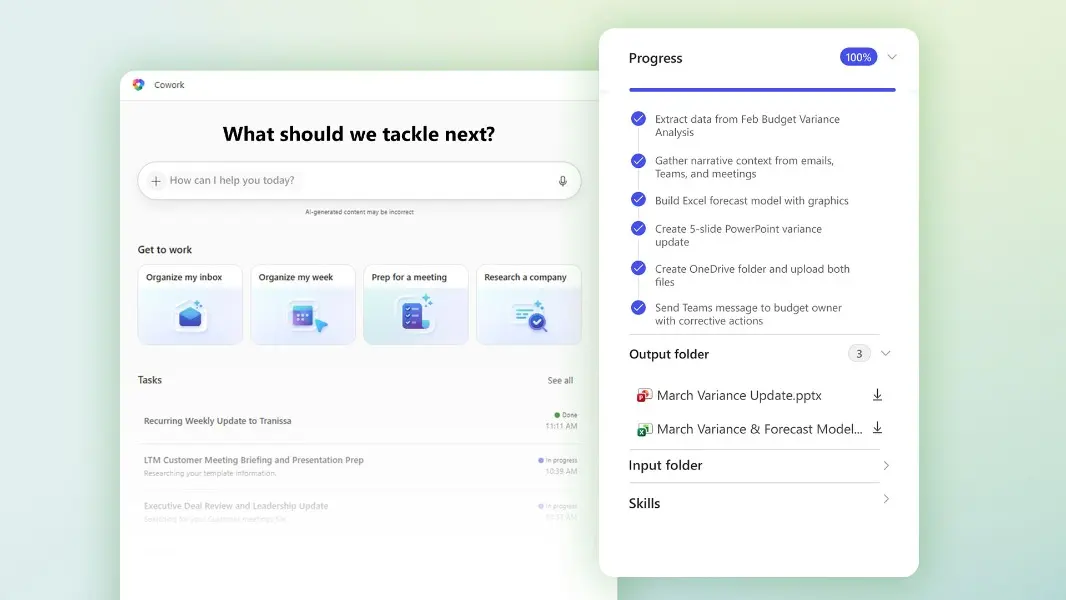
The other headline announcement is that Copilot Cowork is now available through Microsoft’s Frontier early access program. Cowork is built for a fundamentally different kind of work than traditional Copilot interactions. Where standard Copilot responds to individual prompts (summarize this email, draft this document), Cowork is designed to handle long-running, multi-step tasks that span multiple applications.
The concept is delegation. You describe what you’re trying to accomplish, and Cowork creates a plan, then executes across Microsoft 365 apps. It pulls data from Excel, drafts communications in Outlook, updates documents in Word, and coordinates across Teams, all while you monitor progress and step in to steer when needed. It’s the difference between asking an assistant to write a paragraph and asking an assistant to manage an entire project workflow.
Microsoft has been open about the fact that Cowork is built on technology from Anthropic’s Claude Cowork product, which has gained significant traction as a standalone tool for autonomous task management. By integrating that capability into the Microsoft 365 ecosystem and grounding it in organizational data through the Work IQ framework, Microsoft is trying to combine Claude Cowork’s agentic strengths with the enterprise data access and security controls that large organizations require.
Capital Group, one of the early Frontier participants, has already signaled enthusiasm. Their SVP of Enterprise Technology described Cowork as being fundamentally about taking real action (connecting steps, coordinating tasks, and following through across workflows) rather than simply generating content.
Step back from the individual feature announcements and a larger strategic pattern comes into focus. Microsoft is moving away from a single-model dependency and toward a multi-model orchestration layer. Critique uses GPT and Claude together. Model Council surfaces their differences. Cowork leverages Anthropic’s agentic technology within Microsoft’s ecosystem.
Nicole Herskowitz, corporate vice president of Microsoft 365 and Copilot, framed it directly: having various models from different vendors in Copilot is attractive, but Microsoft is now taking it to the level where customers get the benefits of models working together.
This matters for a few reasons. First, it’s a pragmatic response to the reality that no single model excels at everything. GPT and Claude have different strengths, different failure modes, and different reasoning styles. Combining them isn’t just additive. It’s corrective. Each model catches errors the other might miss.
Second, it’s a competitive hedge. By integrating deeply with both OpenAI and Anthropic, Microsoft insulates itself from the risk of any single AI partnership underdelivering. If one model family leaps ahead in capability, Microsoft can shift the balance of its orchestration layer without rebuilding from scratch.
Third, and this is probably the most important one for enterprise customers, it directly addresses the hallucination problem. That’s been the single biggest obstacle to AI trust in business settings. A model reviewing its own output for errors is inherently limited, because it tends to be blind to its own mistakes. A different model reviewing that output brings genuinely independent judgment to the evaluation. It’s not a perfect solution, but it’s a meaningful structural improvement over the single-model status quo.
All of this innovation arrives against a backdrop of stubbornly slow Copilot adoption. Microsoft reported 15 million paid Copilot seats in January. That’s impressive in absolute terms, but it represents only about 3.3% of its 450 million commercial Microsoft 365 users. And the gap between available seats and active, daily usage is likely even wider.
The reasons for that gap are well documented. Output quality doesn’t always justify the editing time required. There’s a steep learning curve around effective prompting. The experience is inconsistent across different Microsoft 365 applications. And the $30-per-user-per-month price point demands clear ROI.
Today’s announcements take aim at the quality and trust dimensions of that problem. Critique should produce more reliable research outputs. Model Council should give users more confidence in what they’re reading. Cowork should deliver value that goes beyond one-off text generation and into genuine workflow automation. Whether these improvements are enough to bend the adoption curve is the open question.
The trajectory Microsoft is setting here has implications well beyond its own product line. If the multi-model approach delivers on its promise (and the DRACO benchmark improvement suggests it can), expect other enterprise AI platforms to follow suit. The era of single-model AI products may be ending, replaced by orchestration layers that treat models as interchangeable, composable components.
For organizations evaluating or already deploying Microsoft 365 Copilot, the immediate action items are pretty clear. If you have access to the Frontier program, Cowork is worth testing against your most repetitive multi-step workflows. If you’re using Researcher, Critique is available now and the quality improvement should be noticeable right away. And if you’ve been holding back on broader Copilot deployment because of trust concerns, Model Council offers a new way to validate outputs before acting on them.
The most interesting thing about today’s announcements isn’t any single feature. It’s the underlying bet that AI gets better when models check each other’s work. That’s not just a product strategy. It’s a design philosophy. And if Microsoft is right, it could reshape how every enterprise AI tool is built from here on out.
Microsoft 365 Copilot’s Critique and Model Council features are available now for Copilot licensees. Copilot Cowork is available through the Frontier early access program.
Venture funding reached a record-shattering $300 billion in Q1 2026 as investors pivot toward agentic AI and energy infrastructure, marking a new industrial era.

IonQ just shattered the $100 million revenue ceiling, proving that quantum computing is no longer a science experiment but a massive commercial reality for 2026.

Tariff chaos and an AI reality check are crushing tech valuations. Discover why 2026’s market whiplash is actually a prime contrarian buying opportunity.
Microsoft is betting that two AI models working together are better than one, and it just shipped the proof.
As of this morning, Microsoft’s approach to enterprise AI took a notable turn. The company announced a batch of updates to Microsoft 365 Copilot that include a feature called Critique, the broader availability of Copilot Cowork, and a new Model Council capability. All of them point toward a future where multiple AI models collaborate within a single workflow rather than competing for dominance. These aren’t incremental polish. They represent a real philosophical shift in how Microsoft thinks about AI reliability, and they arrive at a moment when the company badly needs to accelerate Copilot adoption across its massive customer base.
So let’s break down what’s new, why it matters, and what it signals about where enterprise AI is heading.
Critique is a new feature inside Copilot’s Researcher agent, and its premise is elegantly simple. Instead of having one AI model do all the work, you split the job between two. OpenAI’s GPT handles the initial drafting: planning a research task, synthesizing sources, and generating a comprehensive response. Then, before that response ever reaches the user, Anthropic’s Claude steps in as a reviewer, evaluating the draft for accuracy, completeness, and citation quality.
Think of it as a built-in editorial layer. One model writes. Another model fact-checks. The division of labor mirrors how human research teams actually operate. The person who drafts a report is rarely the same person who reviews it. By separating generation from evaluation, Microsoft is tackling one of the most persistent pain points in AI-assisted work: that nagging question of whether you can actually trust what the model just told you.
The results, at least by Microsoft’s own metrics, are significant. The company reports that the multi-model Critique workflow improved Researcher’s score on the DRACO benchmark (an industry measure of deep research accuracy, completeness, and objectivity) by 13.8%. According to Microsoft, that puts Copilot Researcher ahead of standalone deep-research tools from OpenAI, Google, Perplexity, and Anthropic individually.
Microsoft has also indicated that the workflow will eventually become bidirectional, meaning Claude could draft while GPT critiques. The flexibility to swap roles depending on the task suggests this isn’t just a one-off integration. It looks like the beginning of a broader multi-model architecture.
Alongside Critique, Microsoft introduced Model Council, a feature that lets users compare responses from different AI models side by side within the Researcher experience. Rather than receiving a single blended answer, users can see where models agree, where they diverge, and what unique perspectives each one brings to the table.
This is a subtle but important move. One of the biggest barriers to AI trust in enterprise settings is the black-box problem. Users get an answer, but they have no way to gauge its reliability beyond their own expertise. Model Council doesn’t eliminate that problem, but it gives users a much richer signal. If two independent models arrive at the same conclusion through different reasoning paths, your confidence goes up. If they disagree sharply, that disagreement itself is valuable. It tells you to dig deeper before acting.
For research-heavy roles like analysts, consultants, legal professionals, and strategists, this kind of comparative visibility could be genuinely transformative. It moves AI from “here’s an answer, take it or leave it” to “here are multiple informed perspectives, now you decide.”
The other headline announcement is that Copilot Cowork is now available through Microsoft’s Frontier early access program. Cowork is built for a fundamentally different kind of work than traditional Copilot interactions. Where standard Copilot responds to individual prompts (summarize this email, draft this document), Cowork is designed to handle long-running, multi-step tasks that span multiple applications.
The concept is delegation. You describe what you’re trying to accomplish, and Cowork creates a plan, then executes across Microsoft 365 apps. It pulls data from Excel, drafts communications in Outlook, updates documents in Word, and coordinates across Teams, all while you monitor progress and step in to steer when needed. It’s the difference between asking an assistant to write a paragraph and asking an assistant to manage an entire project workflow.
Microsoft has been open about the fact that Cowork is built on technology from Anthropic’s Claude Cowork product, which has gained significant traction as a standalone tool for autonomous task management. By integrating that capability into the Microsoft 365 ecosystem and grounding it in organizational data through the Work IQ framework, Microsoft is trying to combine Claude Cowork’s agentic strengths with the enterprise data access and security controls that large organizations require.
Capital Group, one of the early Frontier participants, has already signaled enthusiasm. Their SVP of Enterprise Technology described Cowork as being fundamentally about taking real action (connecting steps, coordinating tasks, and following through across workflows) rather than simply generating content.
Step back from the individual feature announcements and a larger strategic pattern comes into focus. Microsoft is moving away from a single-model dependency and toward a multi-model orchestration layer. Critique uses GPT and Claude together. Model Council surfaces their differences. Cowork leverages Anthropic’s agentic technology within Microsoft’s ecosystem.
Nicole Herskowitz, corporate vice president of Microsoft 365 and Copilot, framed it directly: having various models from different vendors in Copilot is attractive, but Microsoft is now taking it to the level where customers get the benefits of models working together.
This matters for a few reasons. First, it’s a pragmatic response to the reality that no single model excels at everything. GPT and Claude have different strengths, different failure modes, and different reasoning styles. Combining them isn’t just additive. It’s corrective. Each model catches errors the other might miss.
Second, it’s a competitive hedge. By integrating deeply with both OpenAI and Anthropic, Microsoft insulates itself from the risk of any single AI partnership underdelivering. If one model family leaps ahead in capability, Microsoft can shift the balance of its orchestration layer without rebuilding from scratch.
Third, and this is probably the most important one for enterprise customers, it directly addresses the hallucination problem. That’s been the single biggest obstacle to AI trust in business settings. A model reviewing its own output for errors is inherently limited, because it tends to be blind to its own mistakes. A different model reviewing that output brings genuinely independent judgment to the evaluation. It’s not a perfect solution, but it’s a meaningful structural improvement over the single-model status quo.
All of this innovation arrives against a backdrop of stubbornly slow Copilot adoption. Microsoft reported 15 million paid Copilot seats in January. That’s impressive in absolute terms, but it represents only about 3.3% of its 450 million commercial Microsoft 365 users. And the gap between available seats and active, daily usage is likely even wider.
The reasons for that gap are well documented. Output quality doesn’t always justify the editing time required. There’s a steep learning curve around effective prompting. The experience is inconsistent across different Microsoft 365 applications. And the $30-per-user-per-month price point demands clear ROI.
Today’s announcements take aim at the quality and trust dimensions of that problem. Critique should produce more reliable research outputs. Model Council should give users more confidence in what they’re reading. Cowork should deliver value that goes beyond one-off text generation and into genuine workflow automation. Whether these improvements are enough to bend the adoption curve is the open question.
The trajectory Microsoft is setting here has implications well beyond its own product line. If the multi-model approach delivers on its promise (and the DRACO benchmark improvement suggests it can), expect other enterprise AI platforms to follow suit. The era of single-model AI products may be ending, replaced by orchestration layers that treat models as interchangeable, composable components.
For organizations evaluating or already deploying Microsoft 365 Copilot, the immediate action items are pretty clear. If you have access to the Frontier program, Cowork is worth testing against your most repetitive multi-step workflows. If you’re using Researcher, Critique is available now and the quality improvement should be noticeable right away. And if you’ve been holding back on broader Copilot deployment because of trust concerns, Model Council offers a new way to validate outputs before acting on them.
The most interesting thing about today’s announcements isn’t any single feature. It’s the underlying bet that AI gets better when models check each other’s work. That’s not just a product strategy. It’s a design philosophy. And if Microsoft is right, it could reshape how every enterprise AI tool is built from here on out.
Microsoft 365 Copilot’s Critique and Model Council features are available now for Copilot licensees. Copilot Cowork is available through the Frontier early access program.
Venture funding reached a record-shattering $300 billion in Q1 2026 as investors pivot toward agentic AI and energy infrastructure, marking a new industrial era.
IonQ just shattered the $100 million revenue ceiling, proving that quantum computing is no longer a science experiment but a massive commercial reality for 2026.
Tariff chaos and an AI reality check are crushing tech valuations. Discover why 2026’s market whiplash is actually a prime contrarian buying opportunity.

SanDisk reports a blowout Q2 2026 with $3.03 billion in revenue and $6.20 EPS. Despite the stock being down today, the future valuation remains massive.
